Click here and press the right key for the next slide.
(This may not work on mobile or ipad. You can try using chrome or firefox, but even that may fail. Sorry.)
also ...
Press the left key to go backwards (or swipe right)
Press n to toggle whether notes are shown (or add '?notes' to the url before the #)
Press m or double tap to slide thumbnails (menu)
Press ? at any time to show the keyboard shortcuts
Could Motor Representations Ground Collective Goals?
In virtue of what could two or more agents’ actions have a collective goal?
First of all, I want to explain just the
claim that I'm going to make.
I'm not giving you any arguments here.
I'm just explaining the claim that I'm going to make.
Recall how Ayesha takes a glass and holds it up while Beatrice pours prosecco;
and unfortunately the prosecco misses the glass, soaking Zachs’s trousers.
Ayesha might say, truthfully, ‘The collective goal of our actions was not to soak Zach's trousers in
sparkling wine but only to fill this glass.’
What could make Ayesha’s statement true?
As this illustrates,
some actions involving multiple agents are purposive in the sense that
among all their actual and possible consequences,
there are outcomes to which they are directed
and the actions are collectively directed to this outcome
so it is not just a matter of each individual action being directed to this outcome.
In such cases we can say that the actions have a collective goal.
We understand the notion of collective goal independently of
any kind of states and process.
But now we want to know how does it come
about, what is it in the bees that provides for
the collective goal when they go off and find a
new home, what is it?
And Will and Hinna when they go off and find
a new home together?
And Ayesha and Beatrice filling a glass together?
[As what Ayesha and Beatrice are doing---filling a glass together---is a paradigm case of joint action, it might seem natural to answer the question by invoking a notion of shared (or `collective') intention.
Suppose Ayesha and Beatrice have a shared intention that they fill the glass.
Then, on many accounts of shared intention,]
the shared intention involves each of them intending that they, Ayesha and Beatrice, fill the glass;
or each of them being in some other state which picks out this outcome.
The shared intention also provides for the coordination of their actions (so that, for example,
Beatrice doesn't start pouring until Ayesha is holding the glass under the bottle). And
coordination of this type would normally facilitate occurrences of the type of outcome intended.
In this way, invoking a notion of shared intention provides one answer to our question about what
it is for some actions to be collectively directed to an outcome.
in this part I'm not aiming to contradict that
idea.
I think it is true.
There are such things as shared intentions, and they are
the kind of things that can underpin collective goals.
The crucial thing is that whereas most of the accounts,
including, for example, Michael Bratman's, depends on the idea that
there's just one kind of state that underpins collective goals,
the shared intention.
I think that there are multiple and it can also
include these intra general structures of motor representation.
So I want to make havoc for philosophers,
like the philosopher Michael Bratman's theory of shared intention.
Not by saying, oh, you know, shared intention doesn't underpin
collective goals, but by saying, oh, look, it's one of
many things that underpin collective goals.
And then you have potentially a problem because it's then
the question, why are you singling out that thing rather
than any of these other things?
And how do you accommodate the fact that these things
are not always present and other things are?
And I think these are good kinds of objection, because
they're the sorts of objection that eventually we ought to
be able to answer.
Are there also ways of answering the question which involve
psychological structures other than shared intention? In what follows I
shall draw on recent discoveries about how multiple agents coordinate
their actions to argue that the collective directedness of some
actions to an outcome can be explained in terms of a particular
interagential structure of motor representations.
Our actions having collective goals is not always only a matter of
what we intend: sometimes it constitutively involves motor
representation.
So, so far, all I've done is said.
That's my thesis.
Hopefully it's clear.
Now we need some evidence to
support the thesis, and ideally we need to generate some
novel predictions from it.
When I started working on this with some good
collaborators, Sinigaglia and Sacheli and others, we first of all
worked out what kind of evidence might support this idea.
Then we offered some predictions, which we were able to test.
Quite independently of some
other marvellous groups of researchers, were doing that, generating predictions
from this conjecture.
And then we tested those predictions.
So we have now got quite, quite a good idea of what's going
on.
a clue: when agents perform joint actions, motor representation concerning
a partner’s action can occur.
a clue:
motor representations concerning another’s actions occur in joint action
First of all, background, why might we think that
there are there's anything to do with motive representation that
can help with collective goals.
An important clue as to how we might be in the ‘we mode’ is provided by some experimental
data concerning motor representation in joint action ...
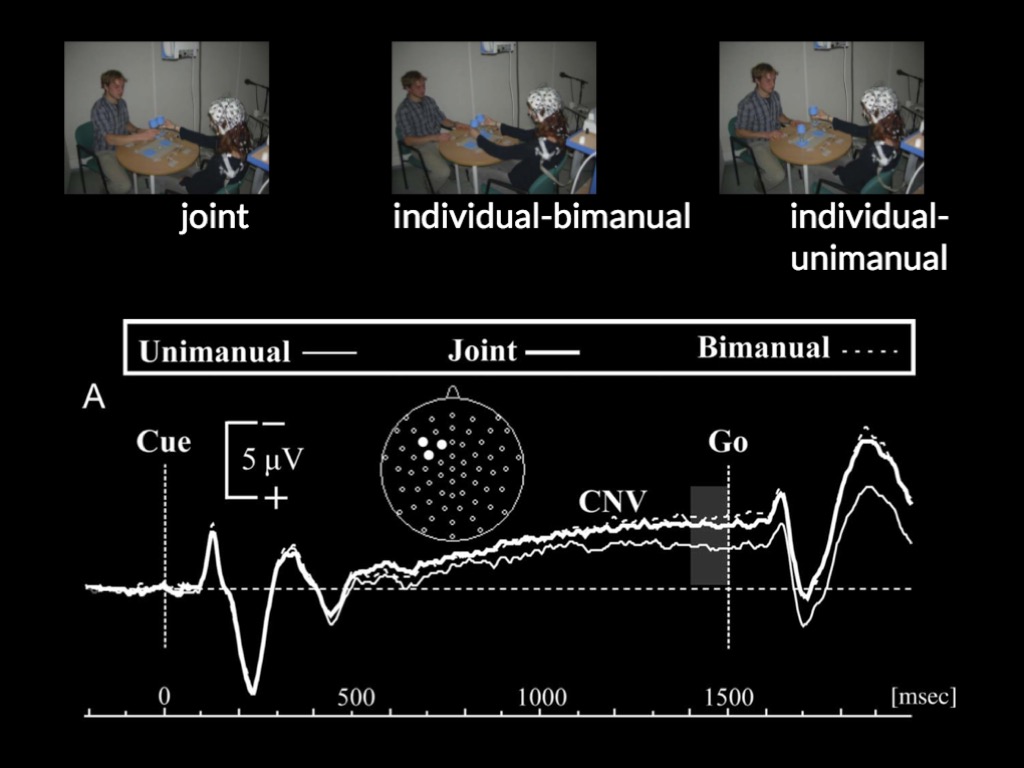
Kourtis, Sebanz, & Knoblich (2013)
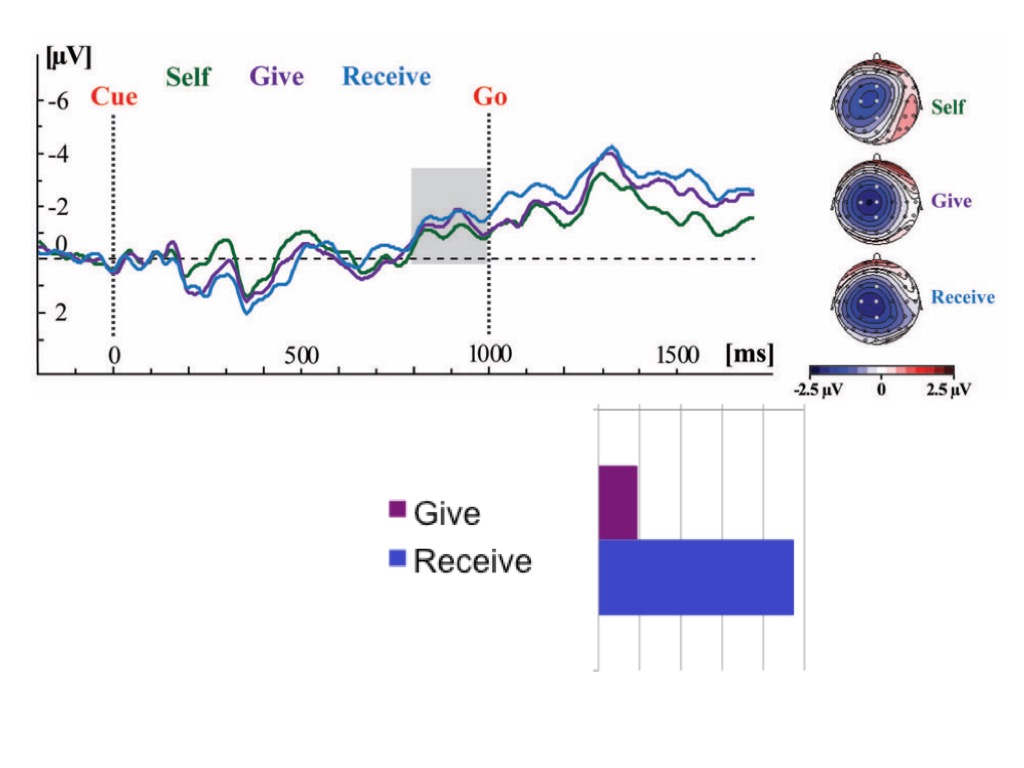
The CNV, an event-related potential, is a signal of motor preparation for action which is time-locked to action onset.
In this research, Kourtis et al show
that the CNV occurs when joint
action partners act, suggesting that when acting together we represent
others' actions motorically as well as our own,
and also that the stronger CNV peak is correlated with better coordination
(Kourtis et al., 2013);
and in earlier research they show, roughly, that a stronger CNV occurs
in relation to actions of others one is engaged in joint action than in
relation to actions of others one is merely observing
(Kourtis, Sebanz, & Knoblich, 2010).
Kourtis et al. (2013)
What Kourtis and colleagues noticed—this is
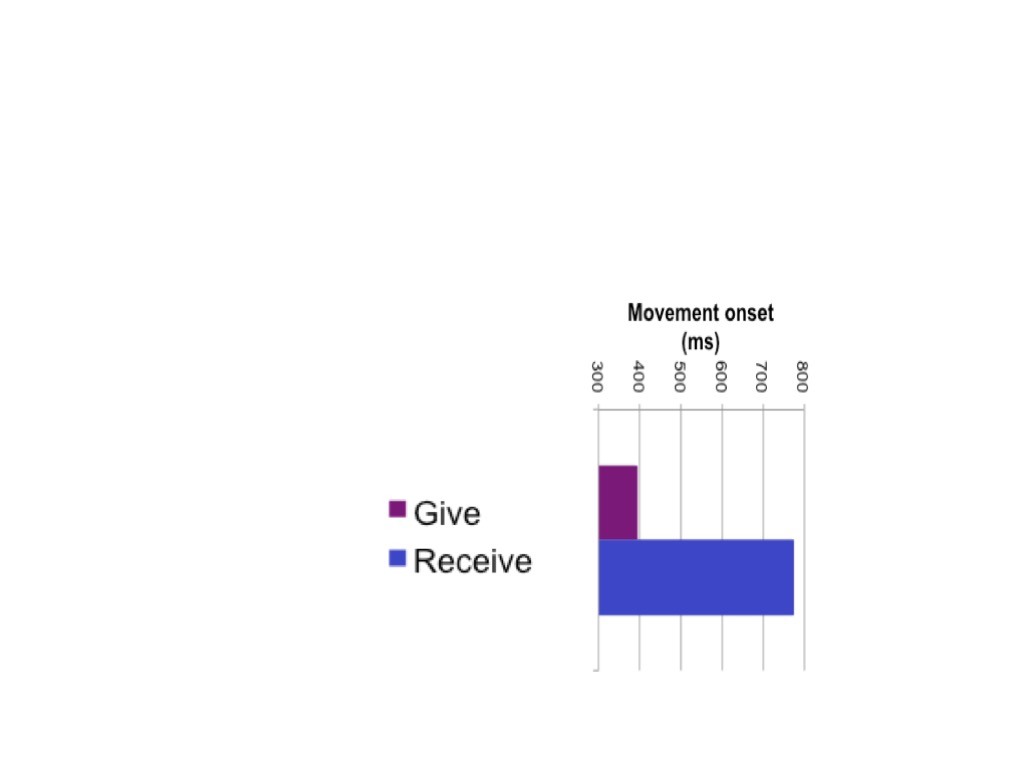
just behavioural—is that when somebody actually moves
their hand varies depending on whether you are giving or receiving.
If you're giving the object it has to move pretty
early 400 milliseconds or so after the go signal, whereas
if you're receiving it, your hand can move a lot
later.
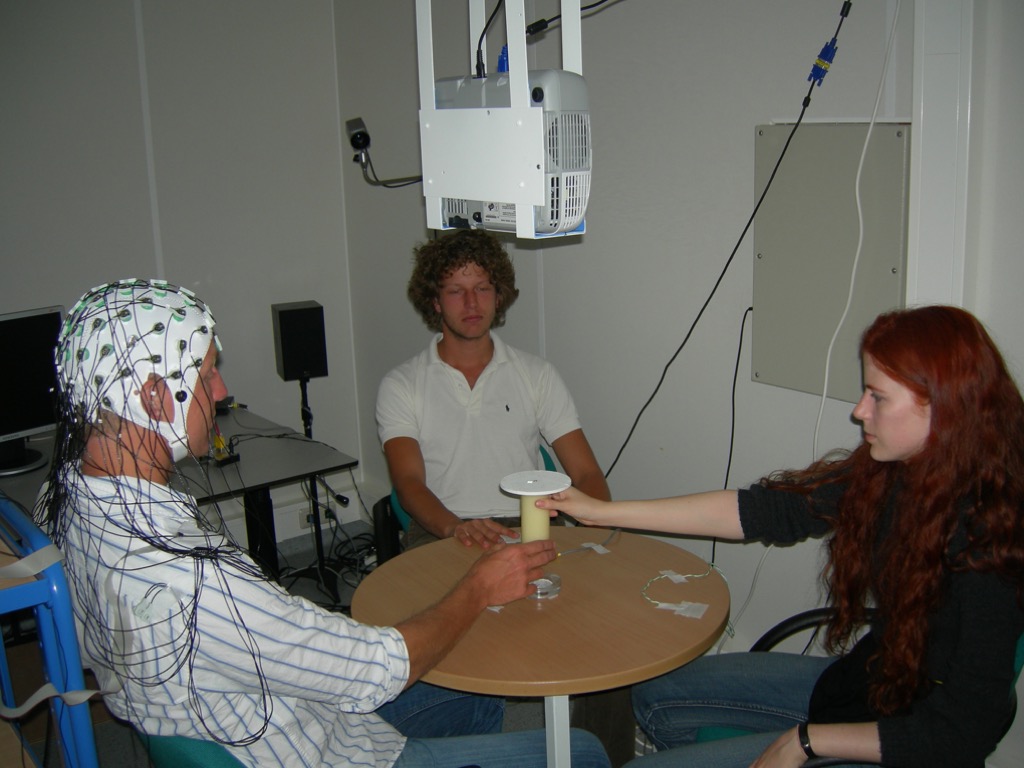
So Billy is passing it to Naran there.
You're passing that nice jug.
He's got to move his hand quite a bit before
Naren does.
Just because Billy's got to get the thing in motion
before Naren really needs to do much.
So there's a nice gap here.
Kourtis et al. (2013, p. figure 5)
But when you look at that signal of motor preparation,
the CNV, this marvellous thing happens.
What you see is that the CNV seems to be
time locked to initiation of the giving action, even when
you're receiving.
The gist of this is that when Billy is passing
that cylinder that you so conveniently brought along today.
(Thank you for that.)
to Naren ...
in Billy there is this motor preparation which is happening
much earlier than it truly should.
Is locked to Naren's action rather than
Billy’s own action.
And that's a signal that, in Billy, something motoric is going on
concerning Naren's action
when they're acting jointly with Naren.
So that's one important clue.
‘the (motor) CNV of a “receiver” peaked approximately at the time of the partner’s response. This suggests that in the receiving 610 condition participants were not only preparing their own actions but also sampling the average speed their partner took to initiate the giving action. This, in turn, allowed them to predict the time their partner would
take to initiate the giving action on a given trial.’
(Kourtis et al., 2013, p. 9)
‘there was a significant correlation between the receiver’s motor CNV
amplitude and the improvement in coordination. The behavioral analysis clearly showed that the speed-up
in receiving led to the improvement in coordination
as receiving was getting faster at a greater rate than giving. This finding can be well explained by the assumption that motor simulation allowed the receiver 655 to predict the timing of the giver’s action and to improve coordination by decreasing the asynchrony in action onset between initiating the giving and receiv-
ing action.’
(Kourtis et al., 2013, p. 9)
Kourtis, Knoblich, Woźniak, & Sebanz (2014, p. figure 1c)
Here’s another clue ...
Second important clue.
Same group of researchers, Kourtis and colleagues.
Now they're starting a contrast between a joint action and
an individual action.
In the joint case, two people are clinking glasses.
So just pick up these glasses and clink them in
the individual by manual case.
One person is clinking both glasses.
And then there's an individual unit manual case, in which
case the participant just picks up the glass and does
as if to clink with the other person while the
other person does nothing.
Kourtis and colleagues thought this on the hypothesis that
the motor representations really are only concerned with one's own
action.
We should find that the joint case and the individual
case are most dissimilar with respect to motor planning, because
in both of those cases, you've got the same individual
action.
By contrast, if you think that there is motor planning
concerning not just your own action, but also the other
person's action, then you actually think that what's happening in
the joint case is the kind of planning for the
participants action and the Confederates action in the participant.
And so in this case, will actually resemble the case
where the participant does the financial action more strongly than
it will represent the case where the participant is now
just doing half of the action.
[I think we're a long way from having a large body of converging evidence for this conjecture,
but there is some that points in this direction.
One of the most relevant experiments is this one by Kourtis et al. (2014).]
They contrasted a simple joint action involving two agents clinking glasses.
The CNV is a signal of motor preparation for action which is time-locked to action onset.
In previous research, Kourtis et al show (i) that the CNV occurs when joint action
partners act, suggesting that when acting together we represent others' actions motorically
as well as our own (Kourtis et al., 2013);
and
(ii) (roughly) a stronger CNV occurs in relation to actions of others one is engaged in joint action than
in relation to actions of others one is merely observing (Kourtis et al., 2010).
Kourtis et al hypothesised that in actions like clinking glasses,
A single outcome represented is motorically,
which triggers planning-like processes
concerning all the agents' actions.
This leads to the prediction that the CNV in joint action will resemble that occurring in
bimanual action more than that occuring in unimanual action.
Kourtis et al. (2014, p. figure 4a)
... and this is exactly what they found.
This is the CNV again.
And what you can see is that the joint case
and the bi manual case have got peaks in the
same places.
And they look really quite different from the manual case,
which is the, the one that you can see are
separate.
From the point of view.
Of your motor system.
Performing an action with somebody else clinking glasses with them
is more like clinking two glasses together yourself than just
moving one glass in isolation.
Why would that be?
Well, the thought was it's explained by the hypothesis that
they were testing that there is motor representation concerning not
just your own actions, but others actions in the course
of joint action.
Ramenzoni et al, 2014 figure 1
[Get them to act out the experiments.
But maybe don’t tell them until later that they used finger tapping
(the figure is just to illustrate the concept.)]
Importantly there is converging evidence for the involvement of motor representation concerning
a partner’s action in joint action from studies which use behavioural measures ...
Joint performance is better when observing joint actors; individual performance when observing
individual actors.
[spoken]
So sometimes people don't
really like EEG
And I always think it's good to be sceptical as long as you are not dismissive.
So it's really important that 've got not just
neurophysiological but also some behavioural markers.
Ramenzoni and colleagues did something really incredible.
They asked a person to imitate a model.
Ramenzoni et al, 2014 figure 1
what they found is that people are actually slightly
worse in that imitation, where there's just one model compared
to when there's two models.
That by itself doesn't tell you very much.
The really cool thing is that ...
Ramenzoni et al, 2014 figure 1
now instead of doing
it with somebody else, you're doing the imitation task alone.
And you can either see two people or one person
and you get this lovely interaction.
So you actually worse now when you're imitating and seeing
two people than when you're imitating one.
Even though across all of the four cases, the task
is exactly the same.
There's one person look at that one person and imitate
their actions.
All this changing is other people around
should be completely irrelevant.
On the hypothesis that your motor system doesn't care about what
other people are doing.
you wouldn't expect any effects here at all.
But on the
hypothesis that in cases of joint action, your motor system
is representing not just your own actions, but also others
actions,
yeah, on this hypothesis, you would expect that actually the
whether you're doing individually or jointly and whether
what you're modelling is individual or joint that could make
a difference.
It would make sense that this is more similar here
than this, and that this is more similar than this
to what you're representing motorically.
That would explain the difference in imitation effects.
So once again we are forced to ask,
What are those motor representations doing here?
Conjecture:
Collective goals are represented motorically.
Simple conjecture.
Collective goals are represented motorically.
Here's the idea.
When Lisa passes the cylinder to Gillian
and Gillian takes it,
Lisa is representing the whole movement of the
cylinder.
Why is this helpful?
Because
there's this problem of coordination between
the two hands.
The two hands have to meet in the in the
right place for the exchange to occur.
And when people pass things between them and it goes,
well, this can happen in a really rapid and fluent
way.
But that problem is actually not very different from the
problem that you have when you're using your own two
hands.
So you take an object in one hand and you
pass it to another hand.
In this case as well, you actually have the same
kind of coordination problem two hands have to meet.
It's just that in one case, they're both yours, and
the other case it's another person's hand in yours.
Solve that problem in the case of two people by
having each of you represent all of the actions.
As long as you two are similar enough, your representation
of their actions and their representation of their actions is
going to be close enough that coordinating with your representation
of their actions will work fine.
It will be like coordinating with their representation of their
actions, because it's close enough.
And so you can solve this two hand coordination problem
with another person in the same way that you solve
it yourself.
Represent the whole action.
Very simple.
So representing collective goals
is potentially a good thing, because it allows you to coordinate
your actions with those of the other person—as long
as you eventually inhibit that actions that you're
not supposed to be performing, of course.
So collective goals represented motorically kind of makes sense.
Theoretically.
You can see that I would enable coordination of action
in lots of cases, like passing an object from one
hand to another.
But that isn't quite enough.
You also want to have predictions and then you want
to test the predictions.
So it's okay to say if we look at the
evidence retrospectively, this kind of fits with the evidence.
But that's not super compelling, of course, because it's very
much post hoc.
That's good, but it's not really quite enough.
The gold standard here is that you make a prediction,
you test the prediction and you see if the world
can refute you.
So two predictions ...
Prediction 1 (della Gatta et al., 2017):
Framing two agents’ simultaneous unimanual actions as joint can induce effects similar to bimanual coupling.
The first prediction is this.
Let me step back here to explain bimanual coupling.
If you ask simultaneously with your two hands to draw
two lines.
The line with your right hand, let's say, is going
to be pretty straight compared to a situation where you're
asked to draw a circle with the left hand and
a straight line with the right hand, keeping them in
sync.
What you should see there, if you were doing it
on paper, is that when you're drawing two lines, the
right hand lines are pretty straight, whereas when you're drawing
the circle with the line, you find overlap in the
right hand line.
That's to say that the right hand line is moving
and sort of forming like a bit of a circle.
It's not a proper circle, but it's become ovalized.
So we can use that ovalization as an index
of how strongly this hand's action.
the round one is influencing the right hand action.
The prediction we made is very simple.
If we're right, the collective goals can be represented motorically.
Then what we should find is that if we create
a situation where two people are acting when they represent
the collective goals methodically, even though one is drawing a
circle and the other is drawing a line, we should
see ovalization in the person drawing the line, even
though the other hand is not moving, it's the hand
of another person.
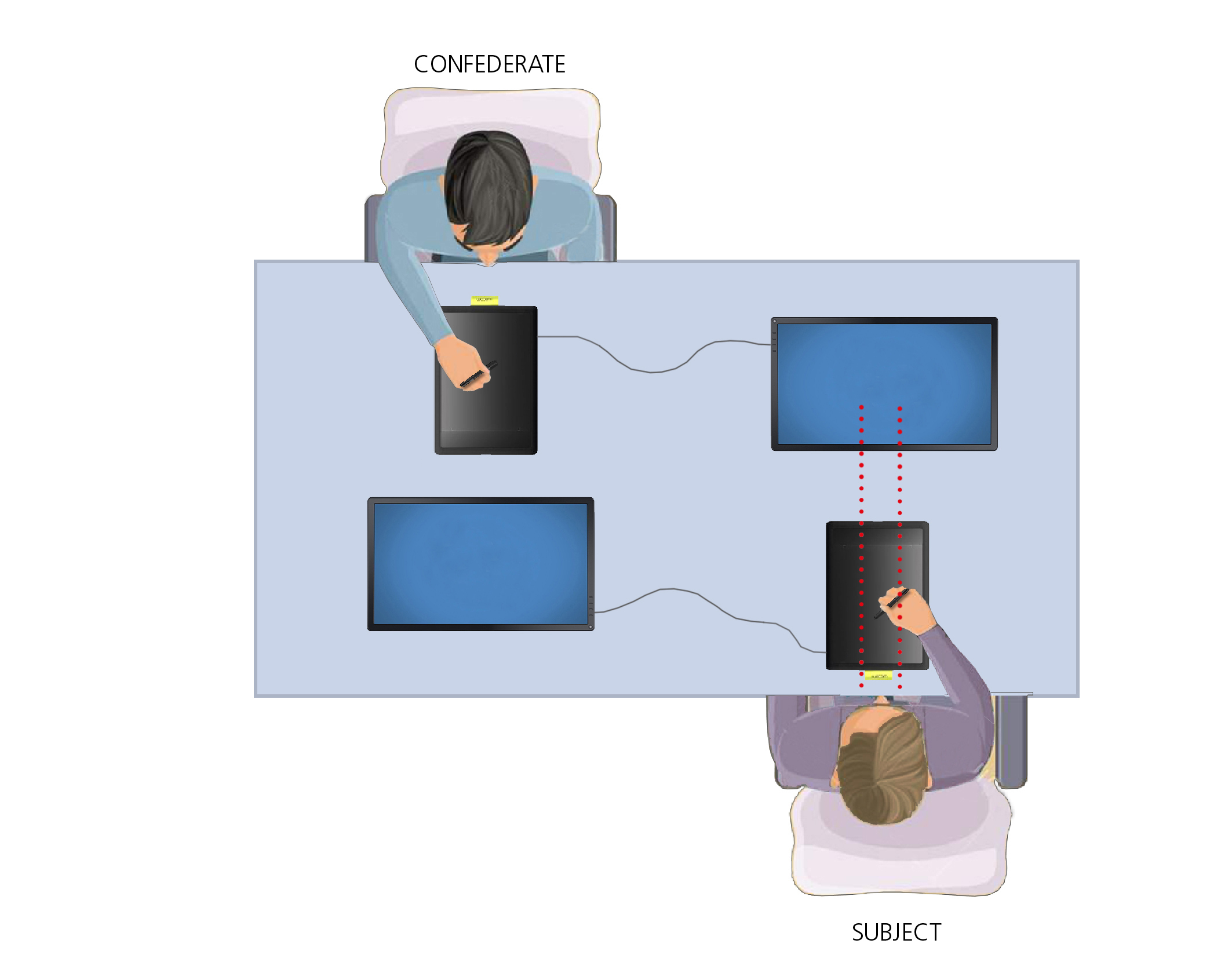
So here's the setup.
The participant is here and is drawing in the case
we're interested in lines on a pad while observing the
output of the Confederate here who is drawing in the
case.
We're interested in circles, and all we're going to do
is measure ovalization between two conditions.
[Condition 1: parallel]
One condition, you're told.
Oh, this is Gabriela.
You and Gabriela are in the business of creating a
design together.
He's going to draw the circle and you're going to
draw the line.
So please pay attention to what Gabriela is doing on
the screen in front of you and synchronise your actions
with Gabriela.
So in this case, we're expecting that people are going
to tend to see this as a joint task and therefore
represent the outcome of the actions motorically, and therefore we're
going to see greater ovalization as compared to a situation
which is exactly the same except for the initial instructions.
[Condition 2: parallel]
So here's this other person and they're
going to draw the circles and you're drawing the lines.
And that's great isn't it.
And I want you to watch what they're doing.
And please synchronise your actions with theirs.
What you find is that across the two conditions, synchronisation
is the same.
Statistically, no difference.
There is well synchronised in the case where we try
to bias them to think individually, as in the case
where we try to bias them, to think jointly.
But you get much more ovalization when you frame
the activity as a joint action than when you frame
it as an individual action, even though the only thing
that differed there was the instructions before you started the
the drawing task, framing it in terms of the joint
rather than the individual.
So this supports the idea that agents, when they experience
themselves as part of a joint action, are likely to
represent
outcomes motorically, where those outcomes are actually specifying things that
involve not only their own actions, but also other people's
actions.
Prediction 2 (Sacheli et al., 2018):
Framing two agents’ sequential actions as a joint action modulates the effects of ‘incongruent’ actions.
Second prediction.
This was a different research group.
Lucia Sacheli and colleagues.
Their prediction, in effect, was that what interferes with your performance is going to
depend on whether or not you frame the action individually
or jointly.
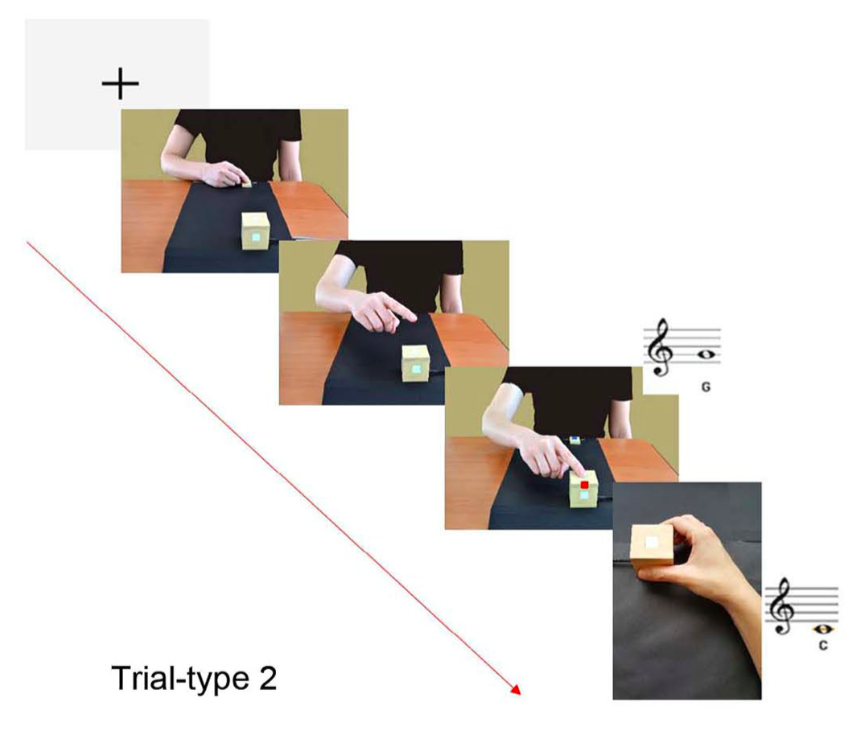
Sacheli et al, 2018 figure 2 (part)
In their task,
this is what you see as a participant.
So the Confederate is either going to tap a box
and create one note.
So taps the box and creates say see or squeeze
a box and creates an E, something like that.
And you can configure the box either so that tapping
creates a D and squeezing creates an E or conversely.
And in the experimental design what happens is the participant
has a go and either taps or squeezes the box.
And you then have to either squeeze or tap the
box.
Sacheli and colleagues divided participants into two groups.
Some of them are told the
Confederate will do some squeezing and tapping, and you're going
to do some squeezing and tapping and that's it.
And then there's a joint action group where the participants
are given a different instruction.
They're told, oh, you and the Confederate are making a
kind of musical sequence together.
But otherwise everything between the conditions is the same.
In both conditions, there is a visual cue which
tells you which note you have to play.
So the framing as parallel or joint is irrelevant
to your tasks.
Across the two conditions, the concrete instructions, what you have to do are
exactly the same.
Sacheli and colleagues introduced to kinds of interference.
[Interference 1] One thing they did was to change the sound
that the box made when the Confederate hit it.
And when they did that, that made a really big
difference to the joint action participants, but almost no difference
to the participants who were in the parallel condition.
[Interference 2] the second kind of interference was
to
change the action
that the
Confederate performs, but not the sound.
So whereas previously the Confederate would tap.
Now the Confederate unexpectedly squeezes it.
But the note they play is the same.
(‘The participants were unaware that, in both conditions, 50% of the trials required either physically congruent or incongruent movements.’)
And what Sacheli and colleagues showed
that this second kind of interference has a really
big effect on the participants who are not engaged in
joint action, but no measurable effect on those who are
given the joint action framing.
In short: there were two kind of interference,
and they had different effect on performance depending
on whether participants’ performance was framed as
individual (/parallel) or joint.
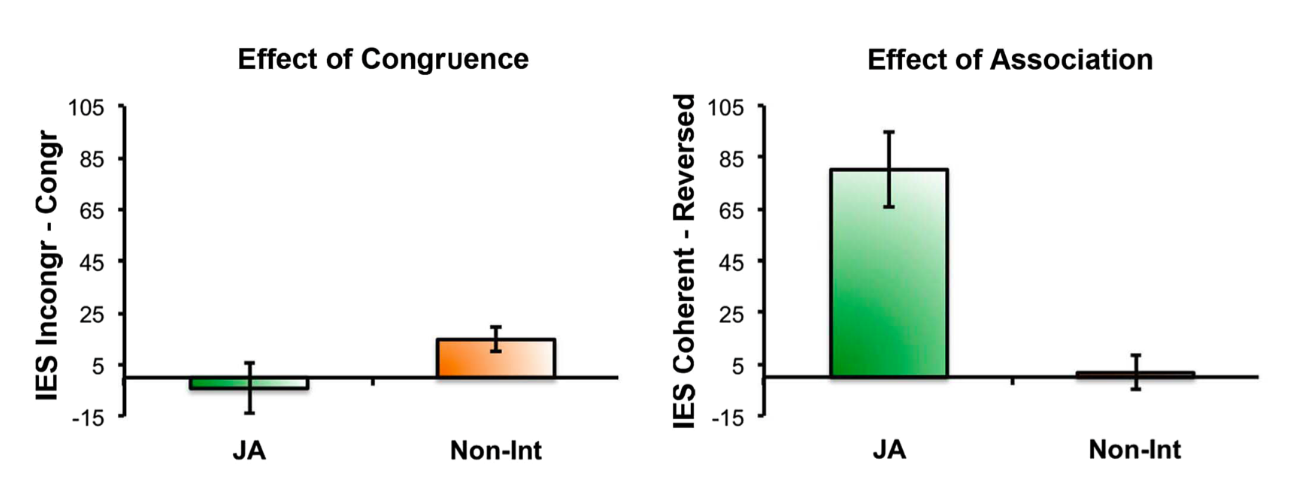
Sacheli et al, 2018 figure 5
So when you change the immediate
form of bodily movement from a tap to a squeeze, that
seems to throw people off in the individual condition.
Seems like they're focussed on that motorically, whereas when you
change the outcome that has no measurable effect on people
in the individual condition who are not thinking of it,
we suppose as a joint action, but very big effect
on people who have framed it as joint action.
Now, what's exciting about these results is that these are imitation
effects.
You do this task hundreds and hundreds of times,
very boring task, these imitation effects.
And you can see here that the this is a
combination of response time and error rate.
The difference in scores is really kind of small.
It's a consequence of the way that the actions are
represented motorically in the joint action case.
What seems to be happening is that you're representing the
tune itself motorically, as an outcome to which actions are
directed.
And that, of course, is a consequence not just of
your actions but the other person's actions.
So you've got a collective goal.
Whereas when you bias
people to frame it in an individual way, it doesn't
seem that they're representing any kind of collective goal, but
they are representing motorically the actions that the other agent
performs so that when they perform an unexpected action or
an action that's incongruent with their own action that they
have to perform that has an effect on their timing.
[Skip -- just in case anyone asks]
Sacheli et al, 2018 figure 3
Conjecture:
Collective goals are represented motorically.
Prediction 1 (della Gatta et al, 2017):
Framing two agents’ simultaneous unimanual actions as joint can induce effects similar to bimanual coupling.
Prediction 2 (Sacheli et al):
Framing two agents’ sequential actions as a joint action modulates the effects of ‘incongruent’ actions.
Some of more recent work goes further: Sacheli, Arcangeli, Carioti, Butterfill, & Berlingeri (2022)
In virtue of what could two or more agents’ actions have a collective goal?
Recall how Ayesha takes a glass and holds it up while Beatrice pours prosecco;
and unfortunately the prosecco misses the glass, soaking Zachs’s trousers.
Ayesha might say, truthfully, ‘The collective goal of our actions was not to soak Zach's trousers in
sparkling wine but only to fill this glass.’
What could make Ayesha’s statement true?
joint action
What is the relation between a joint action and the outcome or outcomes to which it is collectively directed?
Could motor representations also ground this relation? ✓
ordinary, individual action
What is the relation between an instrumental action and the outcome or outcomes to which it is directed?
Motor representations ground this relation.
So here we are again.
We have this question about ordinary individual action.
We know what it is for an event to be
directed to an outcome, but we want to know well
what kinds of actual representations and processes make that true.
And the answer is that sometimes it's motor representation, not
just motor representation can also be intention, can be other
things.
And we're saying parallel question in the case of joint
action, when you've got a collective goal, what makes it
the case that your actions are directed to that outcome
and not any other outcome, that this is the collective
goal of your actions?
We know that sometimes that's likely to be shared intention,
but it's not very plausible to think that in very
small scale cases, like passing a bottle from one place
to another or filling a glass, it will always be
shared intention.
But it seems likely that motor representations can ground
that relation.
That's what we've just been suggesting.
And this is kind of useful for us because.
It allows us to offer a non-standard solution to the
problem of action ...
individual action
joint action
intentions vs motor representations of outcomes
shared intentions vs motor representations of collective goals
Nonstandard Solutions
An action is an event that is appropriately related to a motor representation.
The standard solution to the problem of action says
that what you need is intention.
It is by virtue
of being related to an intention, that an event is
an action.
And we can then say, well, motor representation is also
a candidate, not because we want this to be true,
not because we think this is a true solution, but
because once you've got two solutions that stand side by
side that have parallel virtues, it's much harder to maintain
either of them.
So we're in destructive mode here.
A joint action is an event that is appropriately related to some motor representations of a collective goal.
And similarly in this case we say, okay, so you
think that for something to be a joint action, as
opposed to two people acting in parallel but merely individually,
you've got to have a shared intention.
It looks like you can do something very similar with
motor representations of collective goals.
When you've got motor representations of collective goals in each
of the agents that are providing for the coordination of
the action.
It's doing something that's like a shared intention, but it's
not a shared intention.
So now you've got two answers to the question, and
they seem to have parallel virtues.
And what that indicates is that neither can be correct.
Neither of those answers can be correct.
And this then motivates us to consider alternative solutions.
So we're not saying we can use motor representations to
solve the problem of joint action.
We're saying that if you think about it carefully, motor
representations are just as viable just to have many of
the same virtues as shared intentions for solving the problem
of joint action.
And that tells us that we shouldn't really be thinking
about either solution. (This is why I offered the mechanistically
neutral idea earlier.)
Compare objection to Standard Solution to The Problem of Action
Objection 2 (individual)
The Problem of Action
Invoking motor representations yields a solution that is no worse than the Standard Solution.
Objection 2 (joint)
The Problem of Joint Action
Invoking motor representations of collective goals yields a solution
that is no worse than one which involves invoking Shared Intention.
I’m also picking up where we left off two lectures ago,
but I will not asssume that you remember this so I will drop that part.
plan (from lecture 07)
1. What is the relation between a very small scale instrumental action and the outcome or outcomes to which it is directed? ✓
2. How, if at all, does answering this question challenge the Standard Answer to the Problem of Action? ✓
3. Is there a parallel set of issues concerning joint action? ✓
1. Solve the Problem of Action. ✓
2. Identify a role for motor representation in joint action. ✓